Research Article - Biomedical Research (2017) Volume 28, Issue 9
Vector quantized optimal stage wise video frame classifier for human face recognition
Shirley CP1*, Lenin Fred2, Chitra B31Research Scholar, Anna University, Chennai, Tamil Nadu, India
2Department of Computer Science and Engineering, Mar Ephraem College of Engineering and Technology, Elavuvilai, Kanyakumara District, India
3Department of Electronics and Communication and Engineering, Arunachala College of Engineering for Woman, Nagercoil, Tamil Nadu, India
Accepted date: February 13, 2017
Abstract
Video frame analytic systems are receiving an increasing interest, not only for automatic detection of abnormal events, but also enforcing human face recognition. Recently, many research works have been designed for video frame analytic system. They may fail to reject an operator which gradually builds and refines facial models over time. In this work, a method called, Vector Quantized Optimal Stage-wise Rejecting Classifiers (VQOS-RC) for human face recognition is presented. The VQOS-RC method, works by extracting the video frames from video signals and by classifying them, using Vector Quantized Frame Rejection (VQFR) Module and Least Square Stage-wise Classifier based on an Optimal Reject Threshold factor. The VQFR module rejects unreliable classified video frames using Optimal Reject Threshold evaluation algorithm for reducing false rejection rate. Finally, the Least Square Stage-wise classifier is used for classifying the features in video events thereby improving the classification accuracy. The proposed VQOS-RC technique is analysed in terms of false rejection rate, classification time, classification accuracy. the performance results of VQOS-RC is reduced in terms of false rejection rate by 20% and classification time by 23% and improved the classification accuracy by 13% compared to state-of-art-works.
Keywords
Video frame, Vector quantized, Frame rejection, Least square, Stage-wise classifiers, Human face recognition.
Introduction
Although research in automatic face recognition has been performed in the recent years, it is still an on-going process, due to its various difficulties involving pose variations and varying lighting conditions, recent research works have shifted their area from two dimensions to three dimension representation of human face. 3D face recognition using symmetric surface feature was presented resulting in the improvement of face recognition rate and mean average precision for face recognition purposes [1]. However, for limited or no overlap in directions different to bilateral symmetry, performance improvement was not said to be provided. To address this issue, detector ensembles [2] were used in video surveillance by applying Dynamic Niching Particle Swarm Optimization.
Several techniques have been designed for robust face recognition with improved recognition performance. However, very few works have provided solutions to identify an arbitrary patch of a face image. An alignment free face representation method based on multi-keypoint descriptors in addition to Gabor Ternary Pattern (GTP) was used resulting in the face recognition for both robust and partial faces without requiring alignment [3]. A comparative study by multiple annotators for video classification was presented in [4]. A hybrid Euclideanand- Riemannian metric learning was applied [5] for large scale video-based face recognition. A survey of face detection methods with robust computer vision algorithms were designed [6].
A review of different approaches designed for classification of static and moving object for video surveillance system based on shape and motion was presented [7]. A pose classification framework based on the local Genetic Algorithm based Transfer Vectors was developed [8] to classify the face pose more robustly. An Eigen Probabilistic Elastic Part (PEP) model was designed [9] for improving the face recognition accuracy and ensuring the scalable solution with respect to number of subjects. A comparative study of human action recognition was provided [10].
Vector quantized optimal stage-wise rejecting classifiers are applied to the video images based on the reliable decision factor with optimal threshold value. With the video signal obtained as output, the vector quantized frame rejection is applied aiming at reducing the false rejection rate during transformation. Followed by this, an optimal threshold reject is obtained based on the validity function, with the values below the threshold are rejected and process continued for classification with higher values. The experimental results produced are used to find out the best performance among the existing and proposed classifier models for human face recognition.
The remainder of the paper is organized as follows: the section 3 provides research design that includes the block diagram of the vector quantized optimal stage-wise rejecting classifiers. Section 4 includes an experimental evaluation of the proposed method with parametric definitions. Section 5 discusses in detail by comparing with the existing face recognition and classification methods. Finally, Section 6 outlines conclusions.
Related Works
There have been major changes on the classification schemas for human face recognition over the last few years. In recent years, with the aid of low-level features involving optical flows and spatio-temporal features for representing different actions has become the most popular method for human face and action recognition. Several researchers have proposed high level features including human poses and human-object interactions, resulting in the improvement of face recognition rate. Despite, improvement in face recognition rate, most of these high-level feature work only on still images whereas motion characteristics were not taken into consideration.
Fine grained human action was performed using multiple clues for efficient classification of actions [11]. Local directional binary pattern for facial expression based on video was applied resulting in the improvement of accuracy [12]. Segregation for low and high density was performed and based on classification part-based human detector was applied for high density ensuring recognition performance [13]. Spatiotemporal cues were applied on the video datasets to improve the performance of video object instance search and localization [14]. Another method utilizing spatio-temporal video segmentation was applied to handle large displacement with significant occlusions [15].
A plethora of face recognition approaches by several authors were provided in the recent years. Yet another face recognition model by embedding the low-resolution probe images with that of the high-resolution gallery images was provided [16] in such a manner that the distance between low and high resolution images approximated the distance. This was ensured using an iterative majorization algorithm, resulting in the image recognition improvement. Face recognition was performed using Sparse Approximated Nearest Point (SANP) ensuring robust for the images being classified [17]. A super resolution method was presented [18] by applying non- linear mapping on coherent features resulting in the face recognition accuracy. A comprehensive evaluation of face recognition and verification through photometric stereo was presented [19]. Video-to-video face verification using frame based approach was designed [20] ensuring standardized time and reducing computational complexity.
Based on the aforementioned methods, Vector Quantized Optimal Stage-wise Rejecting Classifiers (VQOS-RC) is introduced for human face recognition. The details of Vector Quantized Optimal Stage-wise Rejecting Classifiers (VQOSRC) for human face recognition are presented in the forthcoming sections.
Vector Quantized Optimal Stage-Wise Rejecting Classifiers
An automatic classification of a set of video events that analyses the video signal at two levels of granularity and by classifying them, using two classifiers that operate at different time resolutions is presented. At the first level the VQOS-RC classifies the time frames stage wise, where a time frame is a short segment of the signal whose time span is few dozens of milliseconds where the time frames are partially overlapped. At the second level the VQOS-RC combines the classification outputs obtained on adjacent frames in order to detect events, with each classifier able to reject the samples having an overall consistency below a threshold factor.
Figure 1 shows the architecture diagram of the block diagram of the Vector Quantized Optimal Stage-wise Rejecting Classifiers (VQOS-RC) for video classification. Initially, the pre-processing is done for removing the noise in video frames. After that, the feature selection is carried out for classification. The video signal is fed to the features selection vector, where the features are selected based on the similarity score value. This helps to extract the related features from each frame of a video sequence. Then, it forms as an input to the frame rejection module. The video features are calculated on a frame basis where the selected feature vector sends the selected frame to the Vector Quantized Frame Rejection (VQFR) Module. The VQFR module works on the Frame of Interest (FOI) to the class and either accepting or rejecting the frame of interest when the reliability decision is below a threshold factor ‘V (α)’. The threshold factors value is measured on the basis of optimal reject threshold. Finally, a stage-wise classifier is made to improve the classifier accuracy.

Figure 1: Block diagram of the vector quantized optimal stage-wise rejecting classifiers.
Vector quantized frame rejection (VQFR) module (reducing false rejection rate)
In this section the Vector Quantized Frame Rejection (VQFR) module is explained with the objective of rejecting unreliable classified video frames and therefore improving the recognition performance. Figure 2 shows the Vector Quantized Frame Rejection (VQFR) module.

Figure 2: Vector quantized frame rejection module.
As shown in the Figure 2, the VQOS-RC is based on two factors, i.e. fusion on reliable decision, that identifies patterns (i.e. for human face recognition) falling within ‘x’ and ‘y’ respectively. This proposal is based on the assumption that the patterns that fall into situation ‘x’ might not fall into situation ‘y’ and vice versa. Based on this assumptions, the VQFR module operates in such a manner, rejecting a pattern if or is lower than the optimal reject thresholds and, respectively.
To this aim the VQOS-RC estimated the reliability of the video frame level classifiers ‘αfi’ measured as an integration of two measures. The two factors considered in the VQOS-RC are, the frame of interest ‘αxfi’ that differ from those present in the dataset, ‘DS’ corresponding to various classes ‘CLi and the point which represents the frame of interest ‘αyfi’ in the features space that lies where the regions pertaining to two or more classes overlaps and is expressed as given below.
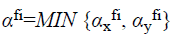 →(1)
→(1)
From Equation 1, the reliable parameter ‘αxfi’ is expressed as given below.
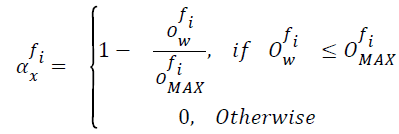 →(2)
→(2)
From Equation 2, ‘Owfi’ corresponds to the distance of frame of interest from closest prototype whereas ‘OMAXfi’ corresponds to the highest value of ‘Owfi’ among all video frames in training dataset ‘DS’, corresponding to the same class. On the other hand, the reliable parameter ‘αyfi’ is expressed as given below.
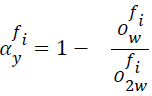 →(3)
→(3)
From Equation 3, the reliable parameter ‘αyfi’ considers the distance of frame of interest from closest prototype and second ‘O2wfi’ closest prototype, but corresponding to different class. Based on the above resultant value, the frame of interest is moved closer if it correctly classifies the obtained features or moved away if it classifies the obtained features incorrectly. The Vector Quantization Frame Rejection (VQFR) module estimates the reliable decision of each feature provided by the classifiers, in this manner, each classifier rejects the frame of interest having an overall consistency below a threshold. Figure 3 shows the vector quantized frame rejection algorithm.

Figure 3: Vector quantized frame rejection algorithm.
As shown in the Figure 3, for each video frame belonging to different classes or two or more overlap classes, the vector quantized frame rejection algorithm, measures the distance of FOI from closest prototype and second closest prototype. With the resultant obtained values, the reliability of video frame is measured, by rejecting the FOI having an overall consistency below an optimal reject threshold that is discussed in the next section.
Optimal reject threshold (improving face recognition rate)
In this section, the design of optimal reject threshold based on the validity function is presented. To this regard, it is assumed that a validity function ‘V’, taking into account the classifier for human face recognition, measures the quality of the classification in terms of correct classification ‘CC’, misclassification ‘MC’ and rejection ‘R’ rates. Under this assumption the optimal reject threshold value in the VQOS-RC determines the trade-off between rejection ‘R’ rates and misclassification ‘MC’ rate, is the one for which the validity function ‘V’ reaches its absolute maximum. Efficient classification for human face recognition is then specified by correlating the costs to misclassifications, rejections and correct classifications.
Let us consider the face patterns for classification problem that belongs to different classes ‘CLi’ with percentage of correct classification of human face recognition being ‘PCC’, percentage of misclassification being ‘PMC’ and percentage of rejection being ‘PR’ respectively. In addition, let the cost associated with correct classification being ‘CCC’, cost associated with misclassification being ‘CMC’ and cost of rejection being ‘CR’ respectively. Then the validity function is expressed as given below.
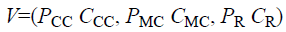 →(4)
→(4)
In order to measure the validity function ‘V’, the VQOS-RC method is designed in such a way that it must be an increasing function with respect to ‘PCC’ and adecreasing function with respect to ‘PMC’ and ‘PR’ and is expressed as given below.
 →(5)
→(5)
In addition to the above condition, another sub condition is added to the VQOS-RC method, that the percentage of misclassification comparatively has higher negative effects on the human face recognition than the percentage of rejection. The sub condition is expressed as given below.
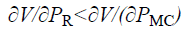 →(6)
→(6)
With the above two conditions assumed, the VQOS-RC method then identifies the optimal reject threshold value ‘α’ being one for which the validity function ‘V’ obtains the maximum value and is expressed as given below.
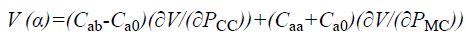 →(7)
→(7)
From Equation 7, ‘∂V/(∂PCC)’ and ‘∂V/(∂PMC)’ are respectively the percentage occurrence curves of correctly classified and misclassified patterns for human face recognition. The term ‘Cab’ denotes the cost of assigning to class ‘b’ a pattern belonging to class ‘a’ (i.e. different classes) whereas the term ‘Caa’ denotes the cost of assigning the patterns to similar class and ‘Ca0’ denotes the cost of rejecting a pattern (i.e. ‘b=0’). Based on the above two assumptions and validation function, the optimal reject threshold evaluation algorithm is designed and provided in Figure 4.

Figure 4: Optimal reject threshold evaluation algorithm.
As shown in the figure, the optimal reject threshold evaluation algorithm estimates reliable decision and performing fusion only on validated reliable decision factors that is used for rejecting unreliably classified patterns. In this way the proposed method arrives at a decision by relying on the patterns on which it is more confident. This in turn improves the face recognition rate.
Least square stage-wise classifier
Finally, stage-wise classifier is performed using the threshold factor within each stage, being approximate monotonic loss function for human face recognition in a stage-wise manner. In order to perform stage-wise classification for human face recognition, the frame length ‘fl’ is considered. The basic idea is to use a stage-wise updated frames ‘fi’, the VQOS-RC method solve the least square problem per stage for several stages. In particular, at the ‘kth’ stage classification is arrived at as expressed below.
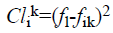 →(8)
→(8)
Let us consider the frame length of ‘6’, with the frame of interest being ‘4’, then the ‘kth’ stage classification is as given below.
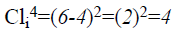 →(9)
→(9)
With the obtained least square problem per stage for several stages as mentioned above, the stage-wise classifier performs classification from ‘4th frame’ to ‘1st frame’ as shown in the Figure 5.

Figure 5: Least square stage-wise frame classifier.
In this manner, the least square stage-wise classifiers introduced for classifying the features in video events, classifies a person by initially discarding most of the faces in memory by sensing small changes between the face to be compared and the faces in the memory. Similarly, each classifier is able to reject the FOI having an overall consistency below a threshold, so increasing the overall performance.
Experimental Setup
Experiments have been conducted on videos from IIT-NRC video-based facial database [21]. The IIT-NRC video-based facial database was created with the aim to examine the computer’s ability to recognize faces and perform a VQOS-RC classifier model. About 20 second of video that consist pairs of 160 × 120 Mpeg-Encoded Video Clips, each showing different faces with different expression has been used to train the feature classification system. The training set is divided into two subsets in order to train both classifiers and subsequently determine through learning the fusion parameters. Comparative analysis was made with state-of-the-art methods, Symmetric meshSIFT (SSIFT) [1] and Detector Ensembles for Face Recognition (DEFR) [2] respectively. Performance analysis were made with certain parameters like false rejection rate, classification time, classification accuracy and recognition rate with respect to different number of identification attempts and varying frame size.
The false rejection rate is the measure of the likelihood that the human face recognition system will incorrectly reject a pattern (from video frame) by an authorized user. On the other hand, the system’s FRR typically is stated as the ratio of the number of false rejections divided by the number of identification attempts.
 →(10)
→(10)
From Equation 10, the false rejection rate ‘FRR’ is arrived at using the number of false rejection rates ‘NFR’ and number of identification attempts ‘NIA’ (i.e. number of images provided as input). The classification time for human face recognition is the time taken to classify the video frames present in sequence of video in order to detect an event. The time taken for classification is mathematically formulated as given below.
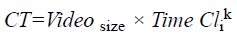 →(11)
→(11)
From Equation 11, the classification time for human face recognition ‘CT’ is measured on the basis of the size of the video ‘Videosize’ with respect to ‘kth’ stage classification ‘(Clik)’ present in video. Lower classification time ensures the efficiency of the method presented and it is measured in terms of milliseconds (ms). Finally, classification accuracy is used as a statistical measure of how well a binary classification test correctly rejects of includes a condition. In other words, the classification accuracy is the proportion of true results (both true positives and true negatives) among the total number of cases (frames) examined.
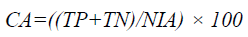 →(12)
→(12)
From Equation 12, the classification accuracy ‘CA’ is the proportion of total number of correct classifications made, including both true positive rate ‘TP’ and true negative rate ‘TN’ respectively.
Discussion
To validate the efficiency and theoretical advantages of the Vector Quantized Optimal Stage-wise Rejecting Classifiers (VQOS-RC) for human face recognition method with Symmetric mesh SIFT (SSIFT) [1] and Detector Ensembles for Face Recognition (DEFR) [2] performance evaluation results are presented. Performance analysis were made with certain parameters like false rejection rate, classification time, classification accuracy with respect to different number of identification attempts and varying frame size.
Impact of false rejection rate
The false rejection rate is measured based on the number of identification attempts made at a particular instance. The false rejection rate is the ratio of the falsely rejection of human face. To better understand the effectiveness of the proposed VQOSRC method, extensive experimental results are reported in Table 1.
| Number of identification attempts | False rejection rate (%) | ||
|---|---|---|---|
| VQOS-RC | SSIFT | DEFR | |
| 5 | 71.32 | 79.32 | 90.14 |
| 10 | 67.14 | 77.38 | 88.25 |
| 15 | 64.32 | 71.34 | 81.24 |
| 20 | 58.32 | 65.32 | 75.83 |
| 25 | 63.14 | 70.14 | 80.24 |
| 30 | 66.89 | 74.29 | 84.37 |
| 35 | 72.14 | 79.89 | 89.28 |
Table 1: Tabulation for false rejection rate.
JAVA language is used to experiment false rejection rate by analysing the result using table and graph values. Results are presented for different number of identification attempts and the results reported here confirm that the results are not linear with the increase in the number of identification attempts. This is because of the noise present in the video frames. The false rejection rate is evaluated in terms of different number of identification attempts in human face recognition. By taking number of identification attempts as 35 in human face recognition is reduced up to 72%. Whereas false rejections rate minimizes for existing methods such that SSIFT method provides false rejections rate as 80% and DEFR method provides false rejection rate as 89%.
Figure 6 shows the false rejection rate based on the number of identification attempts made for human face recognition considered for experimental purpose. Our proposed VQOS-RC method performs relatively well when compared to two other methods SSIFT [1] and DEFR [2]. The false rejection rate is reduced in the VQOS-RC method by applying Vector Quantized Frame Rejection (VQFR) Module. By applying the Vector Quantized Frame Rejection (VQFR) Module, distance of frame of interest from closest prototype and second closest prototype is used to obtain the reliability factor. Based on this prototype values the FOI, moves closer upon correct classification, or moves away upon incorrect classification, therefore improving performance recognition. The Vector Quantized Frame Rejection (VQFR) Module estimates the reliable decision of each feature provided by the classifiers which helps in reducing the false rejection rate by 12% compared to SSIFT [1]. With reliable decision in VQOS-RC method, discards the faces while sensing small changes helps in reducing the false rejection rate by 27% compared to DEFR [2].

Figure 6: Measure of false rejection rate with respect to number of identification attempts made.
Impact of classification time
Classification time with respect to human face recognition is measured on the basis of time to classify the frames for event detection. The targeting results of classification time using VQOS-RC method with two state-of-the-art methods [1,2] in Table 2 presented for comparison based on the size of video for face recognition. To deliver with a detailed performance, in Table 2 video size applies for different face images and ‘kth’ stage classification to obtain the classification time and comparison is made with two other existing methods, SSIFT and DEFR respectively. Lower classification time results in the improvement of the method.
| Size of video (MB) | Classification time (ms) | ||
|---|---|---|---|
| VQOS-RC | SSIFT | DEFR | |
| 113.6 | 40.35 | 57.89 | 61.32 |
| 323.7 | 71.32 | 88.62 | 92.42 |
| 349.5 | 108.14 | 125.52 | 130.32 |
| 454.5 | 105.19 | 121.63 | 143.23 |
| 635.2 | 107.89 | 124.23 | 148.13 |
| 905.3 | 225.67 | 242.13 | 253.23 |
| 936.2 | 268.23 | 268.46 | 281.36 |
Table 2: Tabulation for classification time.
A comparative analysis for classification time with respect to different video sizes was performed with the existing SSIFT and DEFR is shown in Figure 7. The increasing video size of 113.6 MB to 936.2 MB is considered for experimental purpose. As illustrated in Figure 7, comparatively while considering frames with increased size, the classification time also increases. However, with the size of video being 349.5 MB and 635.2 MB, no or minimum change in classification time was observed, though betterment achieved using the proposed method VQOS-RC. This is because of the size of video considered is different for different videos for experimentation. The classification time is performed with respect to size of video in human face recognition. By taking size of video as 936.2 MB in human face recognition, the classification time is minimizes up to 268.23 MB. Whereas classification time minimizes for existing methods such that SSIFT method provides classification time as 268.46 MB and DEFR method provides classification time as 281.36 MB. Therefore, proposed VQOS-RC method provides the better performance on classification time for classify the frames for event detection.

Figure 7: Measure of classification time with respect to different video sizes.
The measurement of classification time is comparatively reduced using the VQOS-RC method when compared to two other existing methods [1,2]. This improvement in classification time is because of the application of the Least Square Stage-wise Classifier. The Least Square Stage-wise Classifier is based on the frame length and ‘kth’ stage classification solves the least square problem per stage for several stages in order to perform correct classification of human faces and rejecting the improper classification. Furthermore, the strategic choice is made based on the frame of interest obtain the frames for classification reducing the rejected classifiers, ensuring classification time by 17% compared to SSIFT [1] and 28% compared to DEFR [2] respectively.
Impact of classification accuracy
In this section to check the efficiency of VQOS-RC method, the metric classification accuracy is evaluated and compared with the state-of-the-art methods, SSIFT [1] and DEFR [2]. Classification accuracy is computed by analysing different set of true positive and true negative rates and is measured in terms of percentage (%). To deliver with a detailed performance, in Table 3 we apply true positive and true negative rate for different set of frames to obtain the classification accuracy and comparison is made with two other existing methods, SSIFT [1] and DEFR [2] respectively. In VQOS-RC method, the classification accuracy with respect to different number of frames is used in the range of 85% to 92%. Whereas classification accuracy is lesser for existing methods such that SSIFT method achieves classification accuracy as 73% to 85% and DEFR achieves classification accuracy in the range of 68% to 80%.
| Number of frames | Classification accuracy (%) | ||
|---|---|---|---|
| VQOS-RC | SSIFT | DEFR | |
| 8 | 85.14 | 73.19 | 68.32 |
| 16 | 88.23 | 76.15 | 63.24 |
| 24 | 90.14 | 82.24 | 77.35 |
| 32 | 84.23 | 76.33 | 71.44 |
| 40 | 88.19 | 80.29 | 75.30 |
| 48 | 90.23 | 82.33 | 77.44 |
| 56 | 92.34 | 85.44 | 80.55 |
Table 3: Tabulation for classification accuracy.
From Figure 8 it is clear that the VQOS-RC method performs better than SSIFT [1] and DEFR [2]. In VQOS-RC method, with an increase in number of frames, the classification accuracy also increases. As shown in Figure 8, the classification accuracy is increased using the proposed VQOSRC method. With the construction of vector quantized frame rejection algorithm, whenever a classification for human face recognition has to be made, the algorithm, measures the distance of FOI from closest prototype and second closest prototype, rejecting the FOI having an overall consistency below an optimal reject threshold. This in turn helps in improving the classification accuracy by 10% compared to SSIFT. In addition, optimal reject thresholds plays a major role in classification, are discarded based on the reliable decision through the integration of two factors, both corresponding to various classes and overlapping classes. As a result, better performance is provided and therefore the classification accuracy is improved by 16% compared to DEFR.

Figure 8: Measure of classification accuracy with respect to different number of frames.
Conclusion
In this work, Vector Quantized Optimal Stage-wise Rejecting Classifiers (VQOS-RC) method for human face recognition is presented. The VQOS-RC method first obtains the video frames and rejects the frame below an optimal threshold factor by applying vector quantized frame rejection module based on reliable decision factor to significantly reduce the false rejection rate for classifying the face for human face recognition. The optimal reject threshold factor is applied to the vector quantized frame rejection in addition to the identification of optimal threshold on the basis of validity function rejecting unreliable classified patterns. Then, least square stage-wise classifier is applied to handle stage-wise classification for different frames with differing frame sizes employing ‘kth’ stage classification to improve the classification time and accuracy. Experimental results demonstrate that the proposed VQOS-RC method not only leads to noticeable improvement over classification time for human face recognition, but also outperforms the classification accuracy on face recognition system. It also reduces the false rejection rate by 20% and classification time by 23% and improved the classification accuracy by 13% compared to state-of-art-works.
References
- Dirk S, Johannes K, Jeroen H, Peter C, Dirk V, Paul S. Symmetric surface-feature based 3D face recognition for partial data, biometrics. International Joint Conference IEEE Biometrics Compendium IEEE RFIC Virtual J 2011; 1-6.
- Christophe P, Eric G, Robert S, Dmitry OG. Detector ensembles for face recognition in video surveillance. International Joint Conference Neural Networks (IJCNN) 2012; 1-8.
- Shengcai L, Anil KJ, Stan ZL. Partial face recognition: alignment-free approach. IEEE Trans Patt Anal Mach Intell 2013; 35: 1-14.
- Gaurav S, Josiah AY, Johnny P, Avinash CK. Using objective ground-truth labels created by multiple annotators for improved video classification: A comparative study. Computer Vision Image Understanding 2013; 117: 1384-1399.
- Zhiwu H, Ruiping W, Shiguang S, Xilin C. Face recognition on large-scale video in the wild with hybrid Euclidean-and-Riemannian metric learning. Elsevier Computer Vision Image Understanding 2013; 117: 1384-1399.
- Stefanos Z, Cha Z, Zhengyou Z. A survey on face detection in the wild: past, present and future. Elsevier Computer Vision Image Understanding 2015; 138: 1-24.
- Pawan KM, Saroha GP. A study on classification for static and moving object in video surveillance system. Int J Image Graph Sign Proc 2016; 76-82.
- Jagdish PS, Alwin DA. A framework for face classification under pose variations. Int Conf Adv Comput Commun Inform 2014; 1886-1891.
- Haoxiang L, Gang H, Xiaohui S, Zhe L, Jonathan B. Eigen-pep for video face recognition. Springer, Computer Vision 2014; 9005: 17-33.
- Haocheng S, Jianguo Z, Hui Z. Human action recognition by random features and hand-crafted features: a comparative study. Springer Comp Vis ECCV 2014; 8926: 14-28.
- Nga HD, Keiji Y. Hand detection and tracking in videosfor fine-grained action recognition. Springer Comp Vis ACCV 2014; 19-34.
- Sahar H, Ali JA, Amir HR. Video-based facial expression recognition using local directional binary pattern. Int J Adv Studies Comp Sci Eng 2015; 4: 7-15.
- Afshin D, Haroon I, Amir RZ, Mubarak S. Automatic detection and tracking of pedestrians in videos with various crowd densities. Springer Pedestrian Evacuation Dynamics 2012; 3-19.
- Jingjing M, Junsong Y, Jiong Y, Gang W, Yap- PT. Object instance search in videos via spatio-temporal trajectory discovery. IEEE Trans Multimed 2016; 18: 116-127.
- Hanqing J, Guofeng Z, Huiyan W, Hujun B. Spatio-temporal video segmentation of static scenes and its applications. IEEE Trans Multimed 2015; 17: 3-15.
- Soma B, Kevin WB, Patrick JF. Multidimensional scaling for matching low-resolution face images. IEEE Trans Patt Anal Mach Intell 2012; 34: 2019-2030.
- Yiqun H, Ajmal SM, Robyn O. Face recognition using sparse approximated nearest points between image sets. IEEE Transactions On Patt Anal Mach Intell 2012; 34: 1992-2004.
- Xiao Z, Hua H. Super-resolution method for multiview face recognition from a single image per person using nonlinear mappings on coherent features. IEEE Sign Proc Lett 2012; 19: 195-198.
- Stefanos Z, Gary AA, Mark FH, William APS, Vasileios A, Maria P, Melvyn LS, Lyndon NS. Face recognition and verification using photometric stereo: the photoface database and a comprehensive evaluation. IEEE Trans Inform Forens Secur 2013; 8: 121-135.
- Norman P, Chi HC, Josef K, Sebastien M, Christopher M. Enrique A, Jose LAC, Mauricio V, Roberto P, Vitomir S, Nikola P, Albert AS, Hui F, Nicholas C. An evaluation of video-to-video face verification. IEEE Trans Inform Forens Secur 2010; 5: 781-801.
- Website, IIT-NRC facial video database. http://synapse.vit.iit.nrc.ca/db/video/faces/cvglab