Research Article - Journal of RNA and Genomics (2023) Volume 19, Issue 2
Path rule algorithm for genome-wide function enablers to reduce the computational problems.
P Sivakumar*
Department of Genetics and Genomics, Bundelkhand University, Uttar Pradesh, India
- Corresponding Author:
- Dr. P Sivakumar
Department of Genetics and Genomics
Bundelkhand University
Uttar Pradesh
India
E-mail: ntltechnology2020@gmail.com
Received: 02-Dec-2021, Manuscript No. RNAI-21-48903; Editor assigned: 07-Dec-2021, PreQC No. RNAI-21-48903 (PQ); Reviewed: 21-Dec-2021, QC No. RNAI-21-48903; Revised: 15-Feb-2023, Manuscript No. RNAI-21-48903 (R); Published: 15-Mar-2023, DOI: 10.4172/2591-7781.1000134
Citation:Sivakumar P. Path rule algorithm for genome-wide function enablers to reduce the computational problems. J RNA Genomics. 2023;19(2):1-6.
Abstract
This same multitude of responsive classifications becomes substantial, but rather a mutation could well subscribe to various classrooms; responsive classifications were always constructed about ranks; college courses have become normally inconsistent, of extra deleterious than favorable exemplars; category brands could still be unclear, but rather commentaries seem from being misapplication, but rather numerous publications of information must be appropriately consolidated to strengthen prognostications. The former 3 components are those subject to research work, with the special emphasis towards overall creation developing any revolutionary approach enabling recursive methylation patterns however and also annotation genetic functionality predictions. This same TPR, which regulates across this same genetic encyclopedia but also furcate categories, sparked their suggested method. Suggested that TPR ensemble approach was distinguished with dynamic 2- substituted knowledge movement which thus penetrates entire regression ensembles, the corresponding following stated principle: Optimistic expectations from each network have the recurrent effect upon their predecessors, whereas unfavorable projections have a strong repetitive effect upon their children. Overall efficiency but also disadvantages underlying that presented technique are demonstrated by bridge findings employing this same reference microorganism S. Cerevisiae, leveraging distinct forms for biomaterial information including comprehensive mathematical study underlying this same TPR methodology.
Keywords
Biomaterials information, Pathway regulation, Genetic activity, Genetic taxonomy.
Introduction
Ranging spanning genetic functioning forecasting including musical identification but instead meaningful environment identification. Computational forecasting for genetic functionality involves computer clustering, multilayer categorization issue with several potentially multitudes more operational categories coordinated that's from some preset hierarchical [1]. Numerous techniques to multilayered categorization have been presented throughout generally, including applicability spanning between. Hierarchically coordinated category categorization has been used throughout many various applications, including an autonomous categorization for World Wide Web pages and this same prediction about enzymes categories using this same enzyme classification [2]. This same Gene Ontology (GO) but instead either operational compendium were this same primary fundamental taxonomy encompassing genetic functionality categories within general context for genetic functionality estimation. Its GO was divided into 3 taxonomies but instead makes made up of hundreds many operational subclasses that are coordinated into any directional aromatic network [3].
Multiple genotype component forecasting methodologies used chart but rather computer teaching modalities these as responsive correlation connections, Bayesian connections, support vector machines, but rather political promises computer applications, imaginary neurological connections, but rather procedures something which combined fully functioning correlation connections mostly with instructional computers which use a supply chain econometric framework rather than a basic arithmetical symphony, since some also supplied prognostications advanced to bigger configurations. Numerous different good potential methodologies include regimented production methodology something which uses classifier training techniques but rather highest percentage techniques to jointly kernelate respectively information factors but rather production brands, as well as techniques something which help enhance GO application forecasting through separating underlying grammatical connections around genotype but rather mechanism [4-7]. Numerous strategies attempted that use their inherent horizontal character for genetic functionality predictions by specifically addressing functionally category connections.
Related works
Optimistic projections for a base station influences its forefathers throughout a sequential manner, whilst also deleterious estimations implications Edmond author's progenies, paying particular attention to the above principle which controls handwritten notes of respectively GO but rather furcate categorizations: Favorable projections for a base station influences there are own forefathers throughout an abstracted, because when deleterious estimations implications Edmond author's progenies. These resultant ensembles encapsulate this same hierarchy taxonomy's operational links amongst operational categories. With us strategy was based on 2 ways that were previously suggested. Because TPR was obeyed simply marking this same child for each node with negativity anytime particular component was changed into negatives using any probability framework which thus integrates structural amino acids interactions information but also this same rigid hierarchy for GO could anticipate genuine pattern functional labeling. However, unlike with our suggested strategy, which promulgates knowledge through very bottoms towards very summit within this same overarching hierarchical, current technique simply perpetuates knowledge towards very base within a particular network.
This same TPR approach may be used either forecast genetic annotating either this same taxonomic stage but rather for particular subgroups within hierarchy functioning categories, because it delivers probability but also organized genetic annotated recommendations. Furthermore, the approach enables researchers to effectively adjust this exchange amongst accuracy but also recollection characteristic defines genetic functional predictions issues through tweaking any unique universal factor. Researchers employed probability SVMs for foundation learning within this same TPR multilevel ensembles technique that estimates genetic functionalities throughout fermentation, although overall technique remains flexible sufficiently could be employed without another probability baseline teacher including different modeling animals. TPR configurations could be very readily combined using government biologically relevant information integrating techniques while modifying underlying mathematical framework, which provides important towards improving predictions effectiveness. Both previous workshops involving ensembles techniques including multilayer education featured a very rudimentary variant as our TPR ensembles approach. Humans introduce an expanded but rather improved variant of one such document throughout attempt to go over these same features but rather hypothetical residences of TPR combinations, their implementation to methylation patterns genomic component forecasting throughout prototype living things, but rather innovative data analysis directions throughout its regard of genomic component hierarchies categorization.
Materials and Methods
These operational categories within either these GO but also furcate classifications were grouped within linear hierarchical therefore may effectively be expressed as any directional network, with vertices corresponding with categories but also arcs corresponding towards interactions amongst categories. For another result, every node matching with this category Ci could be indicated essentially by i. Every set containing Ci's offspring connections is represented through Y child, where every collection containing their grandparents is represented through the average level (i). Furthermore, child (p) signifies information identities from component i's offspring subclasses, whereas ypari represents those identities from i's parental classrooms. Observe thus whereas just 1 mother was permissible within furcate even though this same overarching organization resembles pure trees forests, additional families were possible within this same GO even though their interactions were constructed using network unidirectional acyclic graphs.
Whenever every protein becomes labeled using any certain operational phrase, something that becomes recursively marked using each of their "mother" categories including predecessors. With either GO but also furcate, this scenario seems somewhat differently whenever given genetic variable was neither assigned into some category c Using furcate, x should become be a member for either of c's child categories since every node could even always possess single parents; because that GO was constructed as the straight unbranched network, x could become attributed given subset among c's descendants provided c's descendants have one least multiple grandparents over whom given genetic x was labeled. Figure 1 illustrates when that TPR may be used alongside using furcate classification. Another predictor which observes standard TPR must implement these same very next criteria with every particular instance x, taking into account those progenitors and any particular cluster 1.
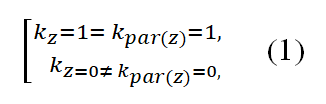
On the other hand, considering the children of a given node z, a classifier that respects the TPR needs to obey the following rules:
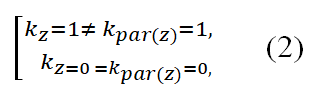

Figure 1: The roots of a furcate bush.
These principles which regulate this same attribution between favorable versus unfavorable designations show significant imbalance. Affirmative expectations propagate through this same foundation toward the very summit within that hierarchy, whereas unfavorable classifications propagate through this same middle toward this same ground [8]. Affirmative expectations could indeed spread through base towards below, whereas unfavorable labeling should transmit between lower parts towards high.
This suggested horizontal aggregation approach combines recommendations from localized basis classifications for every node and creates a neural assembly that thus follows this same correct route rules. The following are these main concepts that underpin this same TPR ensemble automated system:
• Acquisition with foundation students: An appropriate teaching technique gives using classifiers given this same corresponding functionality category every node within network hierarchical.
• These learned classifications connected therewith every category within these networks offer some localized judgment on this same placement for any instance-specific onto any certain location during the overall assessment process.
• Beneficial judgments can spread throughout this same network through bottoms through the highest point, influencing economic judgments for parental units including predecessors through such cyclical manner even though those who traverse this same network towards upper degree single base station. Deleterious choices, by network another hand, have minimal bearing for parental datatype choices.
• Deleterious expectations about every specific component were transmitted among grandchildren throughout order that maintains the TPR hierarchy's coherence. Constructive actions, one network another hand, have minimal impact upon the overall decision-making of other offspring vertices.
Although continuous transmission of unfavorable judgments from topping through basement networks seems simple but instead widespread in conventional multilevel. Leading technique, this same TPR method seems unique in that it propagates favorable judgments through bottoms through summit vertices. Let’s look at how lower descendant's portals influence that choice from their higher branches, this means, researchers, investigate this same impact of grandchildren's good choices upon their predecessors' choices [9]. The overall above study intends to get much deeper knowledge about overall TPR computation properties but also to offer additional academic directions depending upon versions from our suggested color printing methods.
Using furcate, another organizationally social shrub or small, supervised categorization framework that allows comprehensive operational characterization on enzymes across every organism, was used to investigate overall operational categorization of all candida genomes over very methylation patterns resolution covering a significant amount different categories. This same flatten string quartet ignores overall information's organizational architecture but instead essentially gives these same estimates from individual foundation classification educated that identify proteins corresponding within any certain functionality category [10]. For another respect, their outcome simply learning collection if projections produced independently from individual basic learning, including minimal adjustment for organizational links across subclasses. This modular upper edge method classifications every instance x exactly this same follows manner: Dix signifies output classification determination from the network I whereas root represents this same collection containing vertices from this same bottom degree within this same forest T:
Researchers employed 2 distinct forms using SVM baseline trainers across every ensemble. Their suggested exponential matching was used to estimate the overall probability outcome from these same SVMs that compose TPR composites. Employing maximal crossing verification methodologies, individual compositions' effectiveness was evaluated. The internally crossing evaluation was used to choose this same w component within TPR-w clusters. Throughout the majority of those tests, individual TPR clusters' criterion t was adjusted at 0.5. Humans acquired information where features have been displayed by Table 1 as a result of those preparation operations.
| Data set | Description | n-samples | n-feat | n-class |
|---|---|---|---|---|
| Sp sim | Sequence pair-wise similarity data | 3387 | 6247 | 208 |
| PPI VM | PPI data from von mering experiments | 2105 | 2497 | 168 |
| PPI BG | PPI data from BioGRID | 4384 | 5247 | 228 |
| Expr | Gene expression data | 4614 | 264 | 235 |
| Phylo | Phylogenetic data | 2556 | 21 | 180 |
| Pfam-1 | Protein domain log E data from Pfam | 3487 | 5675 | 209 |
| Pfam-2 | Protein domain binary data from Pfam | 3501 | 5021 | 209 |
Table 1. Experimentation using biomaterials information sources.
Researchers calculated Adam as well as Laughlin document ratios for every pairing with candida genomes, resulting in yielding unique symmetrical matrices which reflect candida genome pairing commonalities. Within every grade student, many ways towards selecting unfavorable instances might be used. Adverse instances from every category were chosen in a like way manner that they are not annotated for the classes but belong to the parent class in this work. Only negative examples that aren't too dissimilar to the good ones are chosen in this way.
Results and Discussion
Employing’s four each cent merge approaches, overall outcomes from flats, physically but when symbolically, Tmp, but also repetition compositions were examined. Repetition groups were used in several layered bridge methods. This same international bridge was used to assess the model ensemble's expansion capability, whereas the model inside component was used to choose this same appropriate w value. Using one such method, the overall optimum number of w may be chosen regardless of testing information utilized using outside pass.
This hierarchical measurement offers much better acceptable effectiveness measurement regarding this same categorization of all genetic activities, particularly indicated under evaluating empirical design [11-13]. These findings produced using flattened populations are generally rarely reported since these are almost always much inferior then ones produced using hierarchy composite techniques. TPR-w produces overall greatest outcomes upon aggregate employing combined regular but also probability distribution SVMs underlying foundation learning: 0.34 vs. 0.25 and 0.29 for TPR respectively. HTD populations utilizing regular SVMs, shown well as 0.32 against 0.27 but rather 0.25 for gradient SVMs. 2 TPR-w produces outcomes which thus are on par or significantly superior then HTD groups for many information categories. Examine 3 iterations of 5-fold crossover verification findings every both of 7 sample groups under consideration (Figures 2 and 3).

Figure 2: Flattened populations using hierarchy composite techniques.

Figure 3: F-measures in any hierarchy structure.
Classification
One might limit investigation towards certain subspaces within classification, despite though its major purpose for research project aims simply construct robust hierarchy technique which should be used for forecast this same entire classification system given particular genome. For example, which uses Pfam-1 information, humans acquire an ordinary specificity of 0.79, a mean recollection of 0.48, but instead, an ordinary Fmeasure of 0.58 for this same rose bush grounded at this same nutrient destiny. Furcate category, constituted of 15 endpoints, but instead an F-measure greater than 0.70 for some many courses, maybe just unless hardly yet another supplier of information has been was used for this same hierarchy categorization. This extra material contains additional findings related to certain different clusters from this furcate classification. This is worthwhile mentioning because findings across every tree structure, including further extensively overall every grade students, are heavily influenced by information collection chosen. Moreover, every sort of biomaterials knowledge contains unique chromosomal traits which could correlate to various operational qualities. Genes expressions information derived through statistical studies, such example may prove beneficial when classifying mitochondria categories despite being lesser valuable when classifying others categories (Figure 4).

Figure 4: Furcated courses are arranged into one branch.
Decision threshold
TPR populations produce probability results, however, the computer ensemble's judgment Dix every node I with any particular genetic x was determined by that thresholds. Researchers investigate overall behaviors by using TPR algorithms through altering overall amount at parameter thresholds t among 0 as 1, throughout trying t see if any better selection for t may enhance our ensemble's effectiveness. To understand do so, researchers looked at average organizational accuracy, recollection, and also F-score from 2 TPR-w clusters that had been trained separately. Overall cumulative memory drops year through it the year when overall thresholds become increased, but overall accuracy grows initially beginning, subsequently achieves optimal clean optimum, but also subsequently declines towards metric greatest criterion numbers. This same clean minimum results from this combined impact from lowering either incorrect but also genuine findings when having barrier was raised, despite conflicting consequences affecting accuracy [14]. After all, consequence, whenever this criterion was set high, respectively accuracy but instead recollection suffers significant reductions, resulting in low F-score numbers. Thus the conclusion, adopting some criterion near around 0.5 appears around to represent a relatively reasonable decision, despite although improving particular value might increase ensemble's effectiveness slightly.
Furthermore, researchers looked at as to if localized optimizing approaches may enhance TPR groups' general effectiveness. These findings were examined using a) technologically demanding for every cluster modeling choosing procedures, and b) relative expense tactics. They employed nonlinear SVMs our foundation learning across either situation including just 2 different determines: PPIVM and Phylo. This same aggregate effectiveness using these same hierarchies’ compositions could significantly increase as a direct consequence of these findings acquired using fivefold crossing verification but also internally triple bridge during modeling evaluation. These may sound counterintuitive, however under the above case, wherein instances are likely may being largely misrepresented but also information is likely to contain chaos because overly aggressive choice might contribute towards imbalanced datasets [15]. On the other hand, it may obtain some considerable increase in overall performance by employing localized price solutions. Designers merely established this same expense of misinterpretation of pessimistic illustrations to something but instead the expense of misinterpretation of favorable illustrations to this same proportion of opposite to favorable exemplars throughout this same coaching established to start imposing overhead uses for miscommunications of favorable but rather pessimistic instances for having trained sequential SVMs. For PPI-VM information, researchers saw a significant little increase throughout overall F-hierarchical measurement Repetition organizations had very little reduction from 0.40 into 0.41, whereas TPR organizations saw another minor decline from 0.28 to 0.27.
Conclusion
Throughout these studies, present any novel hierarchy technique towards genetic functionality forecasting that was influenced by empirical TPR but also extends into entire operational classification and transcripts. Within that genomic but also ontology wide predictions that genes involved from S. melanogaster, TPR-w groups beat either fundamental TPR but also garnish composites considerably. This same outcome of this same experiments, as well as a hypothetical independent inquiry of this same flows of knowledge through this same hierarchies grouping, demonstrate what some TPR-w have become well to genomic component prognostication but rather point to innovative data analysis orientations for this same advancement of innovative hierarchy aware genomic configuration forecasting. Essentially, these findings suggest researchers could achieve excellent accuracy but also memory regarding particular individuals throughout Furcate woodland without a solitary resource providing information. Nonetheless, researchers must combine numerous knowledge streams throughout order that develop algorithms for predicting physiological activities for speculative families while discovering in completing existing operational annotating for proteins which functionality remains uncertain but rather inadequate. Toward such purpose, our suggested method may become readily used using as a minimum 3 other generic biomedical information inclusion techniques: Scalar synthesis, spatial incorporation, and spatial assimilation.
References
- Lai MC, Lai ZY, Jhan LH, et al. Prioritization and evaluation of flooding tolerance genes in soybean (Glycine max (L.) Merr.). Front Genet. 2020;11.
[Crossref] [Google Scholar] [PubMed]
- Epping L, Walther B, Piro RM, et al. Genome-wide insights into population structure and host specificity of Campylobacter jejuni. Sci Rep. 2021;11(1):1-5.
[Crossref] [Google Scholar] [PubMed]
- Latchoumi TP, Balamurugan K, Dinesh K, et al. Particle swarm optimization approach for waterjet cavitations peening. Measurement. 2019;141:184-89.
- Schmidt DA, Waterhouse MD, Sjodin BM, et al. Genome-wide analysis reveals associations between climate and regional patterns of adaptive divergence and dispersal in American pikas. Heredity. 2021;127(5):443-54.
[Crossref] [Google Scholar] [PubMed]
- Chandrasekaran S, Danos N, George UZ, et al. The axes of life: A roadmap for understanding dynamic multiscale systems. Integr Comp Biol. 2022;61(6):2011-19.
[Crossref] [Google Scholar] [PubMed]
- Ezhilarasi TP, Dilip G, Latchoumi TP, et al. UIP-A smart web application to manage network environments. Proc Third Intern Conf Comp Intell Inform. 2020;97-108.
- Vianna JA, Fernandes FA, Frugone MJ, et al. Genome-wide analyses reveal drivers of penguin diversification. Proc Natl Acad Sci. 2020;117(36):22303-10.
[Crossref] [Google Scholar] [PubMed]
- Matthey-Doret C, Baudry L, Breuer A, et al. Computer vision for pattern detection in chromosome contact maps. Nat Commun. 2020;11(1):1-1.
[Crossref] [Google Scholar] [PubMed]
- Latchoumi TP, Vasanth AV, Bhavya B, et al. QoS parameters for comparison and performance evaluation of reactive protocols. Intern Conf Comp Intell Smart Power Sys Sustain Energy. 2020;1-4.
- Rani DR, Geethakumari G. A meta-analysis of cloud forensic frameworks and tools. Conf Power Contr Comm Comp Technol Sustain Growth. 2015;294-98.
- Latchoumi TP, Reddy MS, Balamurugan K. Applied machine learning predictive analytics to SQL injection attack detection and prevention. Europ J Mol Clin Med. 2020;7(2).
- Sridharan K, Sivakumar P. A systematic review on techniques of feature selection and classification for text mining. Int J Bus Info Syst. 2018;28(4):504-18.
- Ranjeeth S, Latchoumi TP. Predicting kids malnutrition using multilayer perceptron with stochastic gradient descent predicting kids malnutrition using multilayer perceptron with stochastic gradient descent.
- Manoja I, Sk NS, Rani DR. Prevention of DDoS attacks in cloud environment. Intern Conf Big Data Analy Comp Intell. 2017;235-39.
- Sridharan K, Sivakumar P. ESNN-hybrid approach analysis for text categorization using intuitive classifiers. J Comput Theor Nanosci. 2018;15(3):811-22.