Research Article - Biomedical Research (2018) Artificial Intelligent Techniques for Bio Medical Signal Processing: Edition-II
Simulation of methods for obtaining information flow in distributed network databases based on ecological intelligence algorithm
1Qinhuangdao Vocational and Technical College, Qinhuangdao 066000, PR China
2Henan Finance University, Zheng Zhou 451416, Henan, PR China
Accepted date: August 29, 2017
DOI: 10.4066/biomedicalresearch.29-17-664
Visit for more related articles at Biomedical ResearchAbstract
Biological intelligence algorithms use biological terms and features such as DNA helix models, immune system algorithms, genetic algorithms etc., to elucidate the computational methods. These biologically inspired algorithms defines that all techniques are based on the existing law of nature. The distributed network database has the characteristics of data, work processing, and distribution and so on. When the data is added, the large-scale data can be carried out simultaneously. In this paper, a simple understanding of the distributed network database was obtained on the basis of the selection of ecological intelligent algorithm and ant colony algorithm. The method was obtained according to the information flow of the existing mathematical models and simulation experiments, which was the method with high accuracy.
Keywords
Database, Distributed network, Ant colony algorithm, Simulation
Introduction
Computational thinking has revolutionized the field of medicine and biology in various terms. The convergence of biology and computer science has inspired scientists from both fields in solving different concerns. The algorithms have been designed to understand processes at molecular and cellular levels. The era of predictive and personalized medicine is about to lead revolutions in health care industry [1]. 21st century of research in biology is mainly focusing on system biology, which helps to analyze the bulk of biological information using computational tools. Database has been developed for decades [2]. Database is the core technology of information technology, which has been widely used in various industries [3]. Accuracy requirements for information flow acquisition methods are particularly accurate. Complex biological systems and their components are related with the computational algorithms in various ways such as cell cycle is compared with Approximate Majority (AM) algorithm [4], genetic algorithms and evolution Strategies are used in artificial intelligence techniques [5], etc.
State of the Art
After years of researches and analysis, the theory of distributed network database is basically perfect, and it also can solve the technical problems. Distributed network database has strong application backgrounds and huge application markets in various medical applications, and all countries have invested a lot of manpower, financial resources and material resources in the research of distributed network database. Chueh et al. suggested the application of distributed network database strategies are used to computer-based health-care record system. The study concluded that use of distributed network database strategies can make the computer based medical record system more secure and accessible [6]. First distributed network medical database system was initiated by Blois et al. in 1971 [7]. Distributed network database has obtained the rapid developments, and there is the emergence of a large number of plans, such as the distributed systems of California University at Berkeley. Researches on distributed network database started in China in 80’s. It is also beginning to bear fruits, such as the DMU/FO system developed by Northeastern University. Health information systems and electronic medical records are some major applications based on distributed network database. The distributed network database allows sharing of medical data to physical or geographically separate data sets. This property allows the access of data repositories to different hospitals and departments. In a practical sense, when a patient’s medical records need to be inspected, it gives a direct access to the system. We can store clinical cases, doctor’s advices, medical records (video, images) and prescriptions in this system [8].
Distributed network database is a set of logical data sets of the same system. It is distributed in a number of areas connected by computer networks, and it can get the unified management by a distributed database management system. For the distributed network and database, in order to improve the search speed, the data is scattered in different regions of the different nodes, and the same data is stored in different regions of the nodes, which means that there is a number of sub data. At the same time, the processing of the distributed network data is the distribution of works, which is named the unified working process, and the executions are divided into a plurality of areas in the work, so as to perform more than one node, and it also increases the actual execution and ability to improve the use rate of the resource database. In the data processing and distribution work, the total-work processing and sub-work processing control multiple problems of users at the same time, and a number of deputy secretaries of different regions of the nodes on the data will be read which is caused by the inconsistent data. Because of the unpredictable operations and faults caused by the duplication of work processing, there is the inconsistent data. In order to ensure the consistency of the database data and the secondary data, it is necessary to adopt the method of obtaining high accuracy information flow. In this paper, based on the method of ecological intelligence, a model was established to obtain the information in the distributed network data.
Methodology
The ecological intelligence algorithm is also a kind of quasi ecological algorithm, which includes the genetic algorithm, immune algorithm, ant colony algorithm and so on. At the same time, it is necessary to perform large-scale simultaneous operations. According to the advantages and disadvantages of the ecological intelligence algorithm, the ant colony algorithm has the advantages of large-scale simultaneous computations, fast feedback mechanisms and good searching results. In this paper, ant colony algorithm is chosen to build the model. The accuracy of information flow acquisition method is to increase the same amount of information flow in the distributed network database at the same period. This increase of information flow has a number of sub data, respectively; we use five different information flow acquisition methods to update the data. It is required to update the data in the shortest time, while the number of sub data should be consistent with the total amount of data, so as to determine the numbers. And it means the accuracy of information flow transmission. The results are used as the basis for judging the accuracy of information flow acquisition methods. Its formula is:
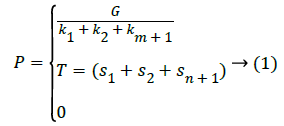
Among themG is the total amount of the increasing data, S is the increasing time of the number of each pair of data and K is the single pair of data which is consistent with the new data.
Result Analysis and Discussion
In order to test the correctness of the model, this paper simulates the urban land construction in a certain area of Shanghai by computer simulation. We assume that within 48 h, there is 10 million new data in the distributed network database of land constructions of Shanghai. Then, we use the traditional work processing method, the extended work processing method, the simultaneous copy control method, the fault time copy control method and the information team method to increase the data. The results are shown in Figure 1.

Figure 1: Five kinds of information flow time.
It can be seen from Figure 1 that compared with the traditional work processing method, the extended work processing method, the simultaneous copy control method and the fault time copying control method, the information team method can achieve a number of new data, and it spends the least time, but it has the highest accuracy, which is considered as a good method.
Conclusion
With the development of the computer technology and the wide use of the Internet in various fields, in order to adapt to the development of the times, the distributed network database is also widely used in various fields, which are relied on by people. The database technology has high updating speed on data and the large-scale data processing at the same time, and the total data and the sub data can meet the requirement of consistency, which shows that the accuracy method on obtaining information flows is an important basis for the distributed database. In this paper, a simple understanding of the distributed network database was obtained, and based on the selection of ecological intelligent algorithm and ant colony algorithm; the method was obtained according to the information flow of the existing mathematical models and simulation experiments, which was the method with high accuracy. In this paper, there were some limitations in the understanding of the information acquisition methods in the distributed network database and the establishment of the model. We hoped to provide some helps for the further study of the later researchers.
References
- Navlakha S, Bar-Joseph Z. Algorithms in nature: the convergence of systems biology and computational thinking. Mol Syst Biol 2011; 7: 546.
- Homer CG, Dewitz JA, Yang L. Completion of the 2011 National Land Cover Database for the conterminous United States-Representing a decade of land covers change information. Photogrammetric Eng Remote Sens 2015; 81: 345-354.
- Yin S, Li X, Gao H. Data-based techniques focused on modern industry, An overview. IEEE Transact Industrial Elect 2015; 62: 657-667.
- Cardelli L, Hernansaiz-Ballesteros RD, Dalchau N, Csikász-Nagy A. Efficient Switches in Biology and Computer Science. Plos Comput Biol 2017.
- Winter G, Periaux J, Galan M, Cuesta P. Genetic Algorithms in Engineering and Computer Science. John Wiley & Sons, New Jersey, USA, 1996.
- Chueh HC, Barnett GO. Client-server, distributed database strategies in a health-care record system for a homeless population. Am J Med Informat Assoc 1994; 1: 186-198.
- Blois MS, Henley RR. Strategies in the planning of hospital information systems. Journee D’Informatique Medicale. Toulouse: Institut de Recherche d’Informatique et d’Automatique; 1971.
- Atilgan Y, Dogan F. Data Mining on Distributed Medical Databases: Recent Trends and Future Directions. International Conference on IT Revolutions 2008.